Pyhton(v3.6)으로 AWS를 활용한 분산 처리 #1 (이전글)
Pyhton(v3.6)으로 AWS를 활용한 분산 처리 #2 (현재글)

프로젝트 내용
1. SAP 의 데이터를 취합하여 SAOP로 AWS Lambda 에 I/F 를 진행
2. AWS Lambda 에서 취합한 데이터를 나누어 Amazon SNS(Simple Notification Service) 를 이용함.
3. Amazon SNS에서 또 다른 AWS Lambda 로 분산하여 데이터를 던지고, AWS Lambda 에서는 관세청 (UNIPASS API)를 SAOP 로 호출하여 XML 기반 데이터를 리턴 받음.
4. 리턴 받은 데이터는 SAP 로 I/F 진행함.
5. 동일하게 Web 에서도 조금 더 빨리 확인할 수 있기를 원하는 데이터가 존재할 수 있기에 기능을 넣음.
6. 기능은 위에서 사용한 로직을 재활용하여 API Gateway 로 값을 던질 수 있도록함.
5. 진행 중에 발생한 오류 역시 Amazon SNS 를 이용하여 오류처리용 AWS Lambda 로 던짐.
6. 오류처리용 AWS Lambda 에서는 사내 RDBMS에 로그를 남김. (에이전트를 통해 운영담당자에게 메일 발송)
5. Amazon SNS 를 맛보다.
Amazon SNS 를 이용하여 관세청 데이터를 처리하는 1개의 Lambda 에 큐를 쌓고 분산처리를 하니 가능해졌다.
'그래서 동시에 몇개까지 처리가 가능할까 ?'
우선 SNS 로 던질때 첫 Lambda의 동작은
1) 500개씩 관세청API에 호출할 목록을 나누어 배열에 담는다.
2) 배열은 루프를 통해 반복하여 SNS 를 호출하여 두번쨰 Lambda에 전달한다.
3) 두번째 Lambda에서는 관세청 API를 호출하고 처리결과는 곧 바로 SAP로 I/F(인터페이스)해준다.
데이터 처리 순서가 중요하지 않았기 때문에 먼저 끝나는놈은 먼저 끝내고 퇴근하면 된다.
(눈치보지 말고, 할거 다 했으면 칼퇴하자)
Amazon SNS 를 처리하려면 boto3라는 라이브러리를 사용해야한다.
#Pyhton 으로 Amazon SNS 호출하는 예제
client = boto3.client('sns')
response = client.publish(
TargetArn = 'arn 값',
Message = 'json 형식으로 가공한 데이터'
Subject = '제목',
MessageStructure='json'
)
그리고 받는쪽에서는 아래 그림과 같이 받는다.

[출처] https://docs.aws.amazon.com/ko_kr/sns/latest/dg/sns-message-and-json-formats.html
여러 값을 활용할 수 있는데 나는 제목과 메시지를 활용하기로 했다.
Subject은 3개의 Lamba 중에 어디서 날린 놈인가, Message는 Lambda 의 결과 값을 넣었다.
이제 큐를 쌓기만 하지말고 동시성 작업에 대해 확인을 해야하는데, 부하를 줄이기 위해 10개씩만 띄우기로 했다.
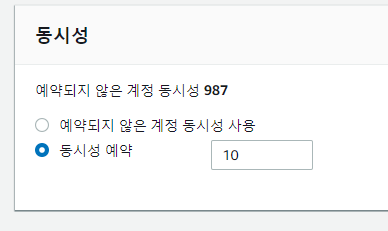
람다1부터 람다3까지 한번에 테스트를 해보니 잘 되는것을 확인하였다.
이거 의외로 너무 쉽게 끝났다.

6. 방심은 금물 웹에서도 호출을 ? API Gateway
아무리 주기적으로 데이터를 끌어온다 한들 실시간하고는 차이가 있을 수 밖에 없다.
결과적으로 수동으로 동작하는것도 필요로 하게 되었고, 이에 대한 고민을 하기 시작했다.
한 번의 액션으로 동일하게 처리하는것은 사실상 불필요하다. 원하는 데이터만 다시 가져오도록 구조를 만들어보자.
다행스럽게도 관세청 API를 호출하는 목록을 처리하는 부분에서 목록이 아닌 단일 데이터를 처리할 수 있는 로직만 추가하면 끝이였다.
그런데 이것을 어떻게 호출하지 ?
사용하고 있는 웹에 기능을 넣는게 가장 알맞겠다. 웹에서 람다를 호출하기 위해서는 API Gateway 라는놈을 만져 줘야 한다.
API Gateway 가 궁금하면 링크로 가서 구경
https://docs.aws.amazon.com/ko_kr/apigateway/latest/developerguide/api-gateway-basic-concept.html
API Gateway 를 만드는 과정은 의외로 간단했다.
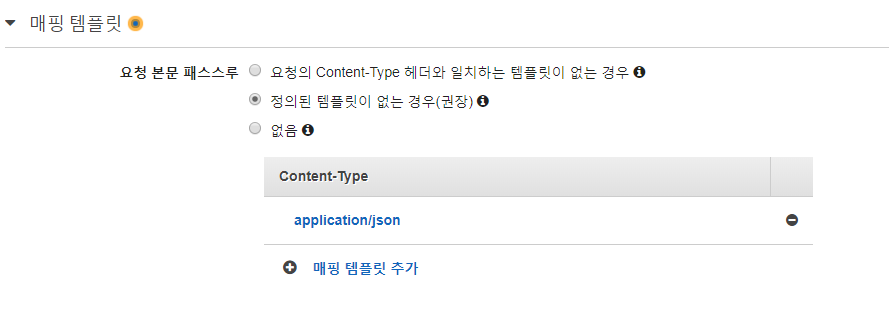
메서드 실행에는 API 를 필요하게 설정을 잡는다.

메서드 실행의 통합요청은 유형에 Lambda 를 체크하고, 매핑 템플릿은 json 으로 했다.

그리고 호출받는 Lambda 에서는 성공시 일단은 "job success" 라는 간단한 문구로 성공했음을 알리도록 했다.
(나중에 이건 변경할 예정이다.)
API Gateway를 배포 진행하고, Postman을 사용해서 테스트를 해봤다.
헤더값에는 x-api-key 값을 넣고..
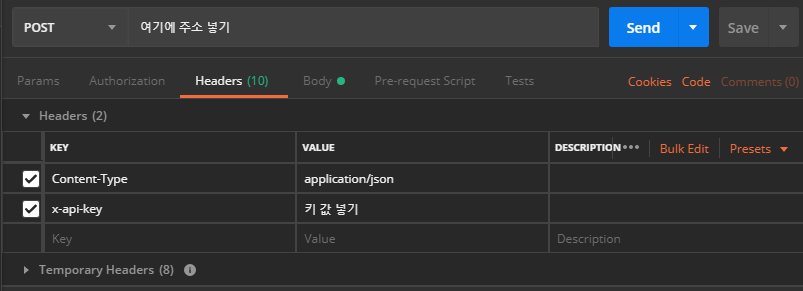

본문에는 위에 Amazon SNS 호출할때 Message 의 형식을 최대한 맞추어 진행한다. Type 을 API 직접 호출과 Cron으로 나누어 해당 Lambda 에서는 어디서 호출되었냐에 따라 로그를 남기도록 수정하였다.
요거로 이제 웹에서 호출하게 하고~ 마무리 해야겠다 했다.

7. 준비는 끝났다.
생각을 해보니 주기적으로 실행을 어떻게 시키나 궁금했다.
클라우드 팀에서 안내해주더라... 클라우드워치로 크론탭기능이 가능하다고...
곧 바로 CloudWatch 통해서 원하는 시간 단위로 호출하는것을 찾아봤다.
규칙이란놈을 넣으면 끝나는군..

규칙 생성을 진행하는데, 이벤트 패턴과 일정 두 가지가 가능하더라.
나는 일정으로 Cron식을 선택하여 매 20분마다 실행하도록 하였다. 그리고 대상 Lambda를 추가했다.

표현식이 궁금하다면 링크를 참고하자.

8. 끝날때까지 끝난게 아니다.. 에러처리!
모든 구성을 마치고 테스트를 진행하는 과정에 에러가 발생했다. 잘돌아가는가 싶더니 에러가 발생했더라.
에러처리가 빠졌다.
에러를 감지해서 어떻게 저장하고 어떻게 알려줘야할까 ?
처음에는 CloudWatch 를 활용해보려고 했다.
우선 클라우드팀의 도움으로 CloudWatch 로그로 에러를 보는법부터 찾는방법까지 안내받았다.
하지만 운영자가 보기에는 너무 어려운 방법이였다.
(본인의 기준으로 사용자를 생각하면 가장 나쁜 개발자!)
CloudWatch 에 가장 깔끔하게 log 를 남기고 그내용을 한번씩 탐지하여 메일발송과 슬랙으로 푸쉬하는것이였다.
너무 기대한걸까?
CloudWatch 의 에러감지는 별로 좋지 않았다. 정확한 에러문구는 날려주지 않는것이었다.
(결국 운영자가 보기에 어쩌구 저쩌구한건 개소리였던걸로...)
'어쩔 수 없이 DB를 사용해야 한다라면 AWS의 DB들중에 골라서 사용할까?' 했지만
내가 지갑을 쥐고 있는것도 아니고...
그냥 사내에 있는 RDBMS를 이용하고 메일 발송으로 안내 하는걸로 했다.
모든 로직에 try catch 를 넣고 exception 내용을 하나하나 잘 담가둔다..
그리고 장애처리 Lambda 를 신규 생성하고 장애내역을 Lambda 로 쏜다..
거기에서는 RDBMS 에 Table에 Insert 한다.
장애는 3가지 유형이 있을것으로 예상된다.
- SAP의 통신 오류
- 관세청 API의 오류
- AWS의 오류
각 Lambda 에 오류처리하는 로직을 넣는다.
이때 SNS를 통해 오류처리용 Lambda 로 전송한다.
오류 처리용 Lambda 는 RDBMS에 데이터를 INSERT 해준다.
그런데...
pymssql 이 동작하질 않는다? 왜지 ?
거의 급발진 마냥 돌진하던 손이 키보드에서 떨어지는 순간이였다.
차분히 찾아보니 이것역시 lxml라이브러리에서 겪은 문제였다.
'분명히... 어느 슈퍼맨이 github에 올려뒀을꺼야..'
없더라~~ 아니면 내가 못 찾은거던가...
결국 EC2에 접속...
그리고 pip3 pymssql install 진행하고 내려받은 놈의 경로로 접근해서 폴더를 몽땅 다운받았다.
SELECT 1 을 날리니 1이 돌아오길래 다 끝났다고 생각했다.
'오늘은 장사접고 위키나 정리해야겠다.' 하고 돌려두는데 이런 python에서 한글이 깨진다.
확인해보니 장애문구를 SNS로 전달하는 과정에 Message 를 json데이터로 변환시켜 값을 넘기는데,
json으로 변환하면 한글이 깨지더라.
(사실 이유를 알아가는 과정속에서 일반적인 프로그래밍언어의 글씨 깨짐 현상을 대처하는 여러삽질을 똑같이 했었다...)
json.dump를 쓸때 ensure_ascii=False 를 넣으면 끝..
9. 에필로그
결국 아래와 같은 구조도로 작업은 종료되었다.
간간히 발생하는 에러는 대부분 관세청API가 잘못된 리턴값을 던지는 경우이고, 현재는 10분 단위로 돌아가고 있다.
우선 작업을 내 멋대로 점점 크게 만드는데도 별 말없이 가만히 방치해둔 현재의 회사 갑님에게 감사합니다.
(물론 처음에는 이랬다 저랬다 어려웠지만..ㅠㅠ)
그리고 서포터를 해준 AWSKRUG의 운영자이자, 클라우드팀 류한진 님에게 감사합니다.
(사실 나는 끌려만 갔다... 이분이 자꾸 '요거를 저거를... 사용하면 된다.' 하면서 나를 살랑살랑 꼬셨다.. )
간간히 기만하게 나의 짜증을 받아준 강대명 님과 가만히 들어준 김대희 님에게 감사합니다.
Pyhton(v3.6)으로 AWS를 활용한 분산 처리 #1 (이전글)
Pyhton(v3.6)으로 AWS를 활용한 분산 처리 #2 (현재글)
'DEV > AWS' 카테고리의 다른 글
| [MASOCON 2019] 컨퍼런스 트랙 - 서버리스를 활용한 분산 처리 DEMO (0) | 2019.11.28 |
|---|---|
| Pyhton(v3.6)으로 AWS를 활용한 분산 처리 #1 (0) | 2019.05.11 |
| Visual Studio Code 로 .NET Core 2.1 사용하여 AWS Lambda 만들기 (0) | 2019.05.08 |


